Fundamentals Of High-Level System Design
High-Level System Design (HLD)
provides an overview of a system, product, service, or process. It’s a generic
system design that includes the system architecture, database design, and a
brief description of systems, services, platforms, and relationships among
modules.
Here are some fundamentals of
High-Level System Design:
1.
System Architecture: The overall structure of the software and the ways in which
that structure provides conceptual integrity for a system.
2.
Database Design: The process of producing a detailed data model of a
database.
3.
Managing Trade-offs: While designing large scale applications, it’s important to
manage trade-offs between consistency, availability, scalability, and
performance.
4.
Key System Resources: Compute, storage, and network resources and how they can be
scaled in a large-scale system.
5.
Building Blocks of Large-Scale Systems: Load balancers, proxies, gateways,
caching solutions, and databases.
6.
Inter-Process Communication: This is key to architecting large
scale micro-service-based applications.
The purpose of HLD is to present
a clear and broad understanding of the system’s performance, scalability, and
functionality. It describes the system architecture, which includes a database
design and a synopsis of the systems’ platforms and services. It also describes
the relationships between the modules present in the system.
In order to excel in system
design, it is essential to develop a deep understanding of fundamental system
design concepts, such as Load Balancing, Caching, Partitioning, Replication,
Databases, and Proxies.
System Design Architectures
System Architecture is the
overall structure of the software and the ways in which that structure provides
conceptual integrity for a system.
There are countless system design
architectures, each tailored to specific needs and contexts. Here's a list of
some prominent ones, along with their pros and cons:
Monolithic Architecture
A Monolithic Architecture is like
a well-built castle – everything's under one roof! All the parts, from
foundation to towers, are tightly packed together. It's simple, efficient, and
easy to manage. But just like a castle, adding rooms or changing the layout
gets tricky, and one big crack can bring the whole thing down.

That's the gist of Monolithic
Architecture in the software world. It's a single codebase where everything's
connected, making it straightforward to develop and deploy. But scaling gets
tough, and changes can be risky. Think of it as a strong foundation for smaller
projects, but less flexible for grand renovations.
Multi-Tier Vs Multi-Layer
In the context of software architecture, the terms “multi-tier” and “multi-layer” are often used interchangeably, but they have distinct meanings:
Multi-layer architecture refers to how the codebase is organized into logical layers. Each layer has a specific role and responsibility within the application. For example, a typical three-layer architecture might consist of a presentation layer (UI), a business logic layer, and a data access layer.
Multi-tier architecture, on the other hand, refers to the physical distribution of these layers across multiple servers or machines. In a multi-tier system, each layer runs on a separate hardware platform. This separation can enhance performance, scalability, and security.
In a monolithic architecture, all the components of the application are interconnected and interdependent. In the context of a monolithic application, multi-layer refers to the organization of code into layers within a single application, while multi-tier would imply that different parts of the application are deployed on different servers.
The three-tier architecture is the most popular implementation of a multi-tier architecture and consists of a single presentation tier, logic tier, and data tier. The following illustration shows an example of a simple, generic three-tier application.

In the two-tier architecture, one tier contains presentation and logic, and data tier. For example, Mobile app contains both UI and business logic and use Api calls to communicate with database.
To summarize, a layer is a logical separation within the application, and a tier is a physical separation of components. Most of the time, it makes sense to split the above-mentioned tiers to achieve further architecture flexibility, synergy, security, and efficiency.
·
Pros: Simple
to develop and deploy, easy to manage and debug, efficient performance.
·
Cons: Not
scalable, tightly coupled components make changes risky, single point of
failure.
Microservices
Architecture
Imagine a bustling city instead
of a castle! Microservices Architecture is like a metropolis where everything
revolves around specialized districts. Each district, a microservice, handles a
specific task like shopping, entertainment, or transportation. They work
together through well-defined roads (APIs) to keep the city running smoothly.

- Pros: Highly scalable and fault-tolerant,
independent deployment and development cycles, agile and adaptable.
- Cons: Increased complexity, challenges in
distributed tracing and debugging, higher operational overhead.
Overall, Microservices
Architecture is like a flexible, adaptable city, perfect for large,
ever-evolving applications. But remember, it comes with its own set of
challenges. ️
Serverless Architecture
Imagine a magical restaurant
where you don't need a kitchen! That's Serverless Architecture in a nutshell.
You focus on crafting delicious dishes (your code), and a trusty wizard (cloud
provider) takes care of the cooking (servers) behind the scenes.

- Pros: Highly scalable and elastic, pay-per-use
model reduces cost, no server management required.
- Cons: Vendor lock-in, potential cold start
latency, limited debugging options, can be expensive for long-running
tasks.
Client-Server
Architecture
Imagine a fancy restaurant with
expert chefs and attentive waiters! That's Client-Server Architecture in a
nutshell.
The kitchen (server) handles
cooking and food preparation, while the waiters (clients) take orders and
deliver meals. Each has clear responsibilities. Waiters communicate orders to
the kitchen, and the kitchen sends back prepared dishes. They work together
through a well-defined process.

All the food and recipes are
stored in the kitchen, ensuring consistency and control. It's like a central
hub for data and services.
- Pros: Clear separation of concerns, improved
security, centralized data management.
- Cons: Increased network traffic, single point of
failure at the server, potential performance bottlenecks.
Event-Driven Architecture
Imagine a bustling cityscape
where things happen in response to events, not schedules. That's the essence of
Event-Driven Architecture. The is genially use in one direction communication.

- Pros: Highly decoupled components, responsive to
real-time events, scalable and reliable.
- Cons: Increased complexity, debugging challenges,
requires robust event handling infrastructure.
Layered Architecture
Imagine a beautiful cake! Layered
Architecture is like building that cake with distinct, delicious layers, each
with its own purpose.

- Pros: Organized and maintainable, promotes code
reuse, simplifies testing and deployment.
- Cons: Can be inflexible, performance overhead due
to layered dependencies, potential bottlenecks at lower layers.
Peer-to-Peer Architecture
Imagine a lively market where
everyone is both shopkeeper and shopper! That's the essence of Peer-to-Peer
(P2P) Architecture, where everyone plays an equal role in sharing resources and
completing tasks.

- Pros: Highly scalable and resilient, no central
point of failure, efficient for sharing resources.
- Cons: Increased complexity, security challenges,
potential for data inconsistencies.
API-Driven Architecture
Imagine a bustling transportation
hub with interconnected trains, buses, and taxis! That's API-Driven
Architecture in a nutshell. It's all about building a system where different
components communicate seamlessly through well-defined routes, like a network
of transportation options.

- Pros: Enables integration with diverse systems,
promotes loose coupling, provides flexibility and scalability.
- Cons: Requires well-defined and documented APIs,
increased security considerations, potential compatibility issues.
Choosing the right
architecture depends on various factors
- System requirements and functionality
- Scalability and performance needs
- Development and operational resources
- Existing infrastructure and constraints
Remember, there's no "one-size-fits-all" architecture. Understanding
the pros and cons of each can help you
make informed decisions for your specific needs.
API
APIs are mechanisms that enable
two software components to communicate with each other using a set of
definitions and protocols.
Think of an API as a
translator for applications. It lets them talk to each other, share data, and work
together seamlessly.
What it is?
- A set of rules and tools for apps to communicate.
- Like a waiter taking orders between a kitchen and
diners.
- Different types: SOAP, REST (most popular),
GraphQL.
How it works
- Client app (like your phone) sends a request
(order).
- Server app (like a weather service) processes and
sends response (food).
- Data flows back and forth through APIs.
Benefits
- Easier development: Use existing code instead of starting from
scratch.
- Faster innovation: Adapt to new needs quickly by changing
APIs, not whole apps.
- Better integrations: Connect different apps and services
effortlessly.
- Wider reach: Offer your data and functionality to others
via public APIs.
Types of APIs
- Private: Internal to a company for connecting
systems.
- Public: Open to anyone, often with fees or
restrictions.
- Partner: Accessible only to authorized external
developers.
- Composite: Combines multiple APIs for complex tasks.
Important aspects
- Endpoints: Specific locations where data is sent and
received.
- Security: Authentication and monitoring to protect
your data.
- Documentation: Clear instructions for developers to use
your API.
- Testing: Ensuring your API works correctly and
securely.
Remember, APIs are the invisible bridges
connecting the software world. Master them, and your app possibilities become
endless!
RESTful API
It's a type of API that follows the REST architectural style, providing a set of guidelines for designing web services.
Representational State Transfer
(REST) is a software architecture that imposes conditions on how an API should
work.
In the context of REST (Representational State Transfer), “Representational State” refers to the state of a resource date at any given moment, which can be represented in a format that the client understands. So, when we say “Representational State”, we’re talking about a snapshot of a resource’s data (state) in a format (representation) that can be understood by the client.
Benefits of RESTful APIs
- Scalability: They can handle large volumes of requests
without performance bottlenecks.
- Flexibility: They are independent of specific
technologies and platforms, allowing for easier development and
integration.
- Independence: Clients and servers are decoupled, enabling
independent evolution and updates.
How do RESTful APIs work?
- Client sends a request: It specifies the desired resource (often
through a URL) and the intended action (e.g., GET, POST, PUT, PATCH,
DELETE) using HTTP methods.
- Server authenticates and processes: It verifies the client's identity and
performs the requested action on the resource.
- Server sends a response: It includes a status code indicating
success or failure, and optionally, the requested data in a structured
format (e.g., JSON, XML).
Additional key points
- Statelessness: Each request is independent and the server doesn't
need to remember past interactions.
- Caching: Responses can be cached to improve
performance.
- Code on demand: Servers can send code to clients for
temporary customization.
- Authentication: Various methods like HTTP basic, OAuth, and
API keys ensure secure access control.
The following are some common
status codes:
1xx (Informational):
- 100 Continue: The server has received the request and is
waiting for the client to continue.
- 101 Switching Protocols: The server is switching protocols as
requested by the client.
2xx (Success):
- 200 OK: The request was successful, and the
requested resource has been delivered.
- 201 Created: The request was successful, and a new
resource has been created.
- 202 Accepted: The request has been accepted, but the
processing is not complete.
- 204 No Content: The request was successful, but there is no
content to return.
3xx (Redirection):
- 301 Moved Permanently: The requested resource has been permanently
moved to a new location.
- 302 Found: The requested resource has been temporarily
moved to a new location.
- 304 Not Modified: The requested resource has not been
modified since the last request.
4xx (Client Error):
- 400 Bad Request: The request was invalid or malformed.
- 401 Unauthorized: The request requires authentication.
- 403 Forbidden: The request was denied by the server (Permissions
check).
- 404 Not Found: The requested resource was not found.
- 405 Method Not Allowed: The requested method is not supported for
the resource.
5xx (Server Error):
- 500 Internal Server Error: An unexpected error occurred on the server.
- 502 Bad Gateway: The server received an invalid response
from an upstream server.
- 503 Service Unavailable: The server is currently unavailable.
- 504 Gateway Timeout: The server did not receive a timely
response from an upstream server.
Idempotency
Idempotency is a property of
operations or API requests that ensures the same result is produced, regardless
of how many times the operation is repeated. It's a fundamental property that
ensures consistency, predictability, and reliability in APIs and distributed
systems.
Key points about idempotency
include:
- Safe methods are idempotent but not all
idempotent methods are safe.
- HTTP methods like GET, HEAD, PUT, DELETE,
OPTIONS, and TRACE are idempotent, while POST and PATCH are generally
non-idempotent.
- Understanding and leveraging the idempotent
nature of HTTP methods helps create more consistent, reliable, and
predictable web applications and APIs.
- Most HTTP methods used in REST APIs are
idempotent, except for POST.
Idempotency is crucial in APIs as
it helps maintain consistency and predictability in situations such as network
issues, request retries, or duplicated requests. For example, in a scenario
where an API facilitates monetary transactions between accounts, idempotency
ensures that only one transfer will occur, regardless of the number of
duplicate requests. This principle simplifies error handling, concurrency
management, debugging, and monitoring, enhancing the overall user experience.
Idempotency is important because
non-idempotent operations can cause significant unintended side-effects by
creating additional resources or changing them unexpectedly when a resource may
be called multiple times if the network is interrupted. This poses a
significant risk when a business relies on the accuracy of its data.
RPC
RPC (Remote Procedure Call) is an architectural style for distributed systems. It has been around since the 1980s. Here are some key points about RPC:
Procedure-Centric: The central concept in RPC is the procedure. RPC APIs allow developers to call remote functions in external servers as if they were local to their software. This means that you can execute procedures on a server as if they were local function calls.
Language Independent: Developers can implement an RPC API in any language they choose. So long as the network communication element of the API conforms with the RPC interface standard, you can write the rest of the code in any programming language.
Communication: Both REST and RPC use HTTP as the underlying protocol. The most popular message formats in RPC are JSON and XML. JSON is favored due to its readability and flexibility.
Abstraction: While network communications are the main aim of APIs, the lower-level communications themselves are abstracted away from API developers. This allows developers to focus on function rather than technical implementation.
Now, let’s discuss the role of Interface Description Language (IDL) and Marshalling/Unmarshalling in RPC:
Interface Description Language (IDL): An IDL is used to set up communications between clients and servers in RPC. You use an IDL to specify the interface between client and server so that the RPC mechanism can create the code stubs required to call functions across the network. The IDL files can then be used to generate code to interface between the client and servers.
Marshalling: Marshalling is the process of transferring and formatting a collection of data structures into an external data representation type appropriate for transmission in a message.
Unmarshalling: The converse of this process is unmarshalling, which involves reformatting the transferred data upon arrival to recreate the original data structures at the destination.

Here are some benefits and limitations of RPC:
Benefits:
- RPC provides interoperability between different implementations.
- A lightweight RPC protocol permits efficient implementations.
- They provide usage of applications in both local and distributed environments.
- They have lightweight payloads, therefore, provides high performance.
- They are easy to understand and work as the action is part of the URL.
Limitations:
- RPC implementations are not yet mature.
- It requires the TCP/IP protocol. Other transport protocols are not supported yet.
- Not yet proven over wide-area networks.
- It can be implemented in many ways as it is not well standardized.
- The Interface Description Language (IDL) is needed to generate subs classes for both client and server.
REST vs RPC
Remote Procedure Call (RPC) and
REST are two architectural styles in API design. RPC APIs allow developers to
call remote functions as if they were local, while REST APIs perform specific
data operations on a remote server. Both are essential in modern web design and
other distributed systems, allowing two separate applications or services to
communicate without knowing the internals of how the other one works.
Similarities
- Both ways to design APIs for server-to-server or
client-server communication.
- Both use HTTP and common formats like JSON or
XML.
- Both abstract network communications.
Key Differences
|
Feature |
RPC |
REST |
|
Focus |
Functions/actions |
Resources/objects |
|
Operations |
Custom
function calls |
Standardized
HTTP verbs (GET, POST, etc.) |
|
Data format |
Fixed by server; limited flexibility |
Any format, multiple formats within same API |
|
Statefulness |
Can be
stateful or stateless |
Always
stateless |
When to use
- RPC: Complex calculations, remote function
calls, hiding processes from client and service-to-service communication.
- REST: CRUD operations, exposing server data
uniformly, easier development.
Why REST is more popular?
- Easier to understand and implement.
- Modern versions like gRPC are performant.
- Faster than RPC.
- More reliable than RPC.
Load Balancing
Load balancing is the method of
distributing network traffic equally across a pool of resources that support an
application. Modern applications must process millions of users simultaneously
and return the correct text, videos, images, and other data to each user in a
fast and reliable manner.

What is Load Balancing?
- Distributes network traffic across multiple
servers for a faster, more reliable experience.
- Increases application availability, scalability,
security, and performance.
Benefits
- Availability: Prevents downtime by redirecting traffic
around failed servers.
- Scalability: Handles traffic spikes by adding or
removing servers.
- Security: Blocks attacks and enhances security
features.
- Performance: Improves response times and reduces
latency.
Types of Load Balancing
Here's a concise version of the
content, covering important points about load balancing algorithms:
Two Categories:
1.
Static: Follow
set rules, independent of server state. Examples:
o Round-robin: Sends traffic to servers in turn
(fair but doesn't consider server load).
o Weighted round-robin: Assigns weights to servers for
priority (better than round-robin).
o IP hash: Maps client IP to a specific server
(sticky traffic, good for sessions).
2.
Dynamic: Consider
server state before distributing traffic. Examples:
o Least connection: Sends traffic to server with fewest
connections (simple but assumes equal workloads).
o Weighted least connection: Accommodates different server
capacities (more efficient than least connection).
o Least response time: Chooses server with fastest response
time and fewest connections (prioritizes speed).
o Resource-based: Analyzes server resource usage (CPU,
memory) for optimal distribution (most versatile).
How it Works
- User requests go to the load balancer.
- Load balancer chooses the best server based on
algorithm and request type.
- Server fulfills the request and sends response
back to user.
Types of Load Balancers
- Application: Analyzes request content (e.g., HTTP
headers) to route traffic.
- Network: Examines IP addresses and network info for
optimal routing.
- Global: Balances traffic across geographically
distributed servers.
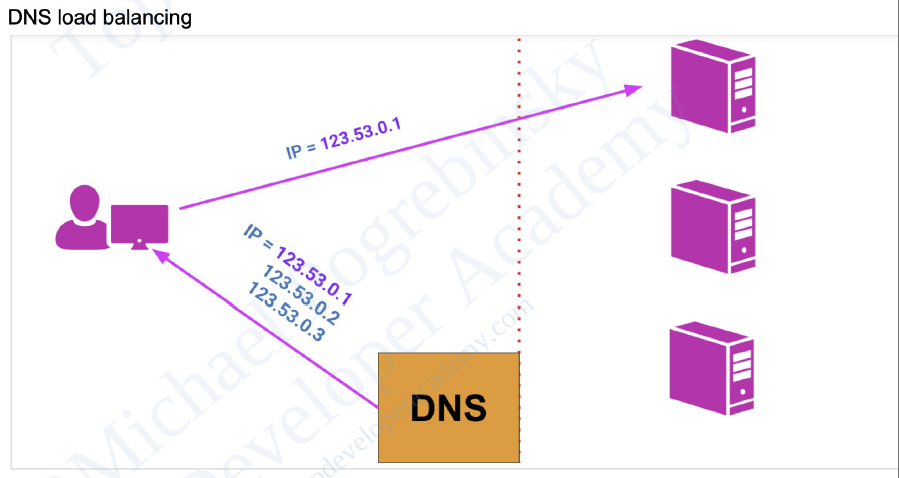
- DNS: Routes requests across resources based on
your domain configuration. It is less secure as it exposes actual server IP address to client.

Types of Load Balancing
Technology
- Hardware: Dedicated appliance for high-traffic
environments.
- Software: More flexible, scales easily, better for
cloud computing.
Key Takeaways
- Load balancing improves application performance
and user experience.
- Different algorithms and technologies cater to
diverse traffic needs.
- Choosing the right type depends on your specific
requirements.
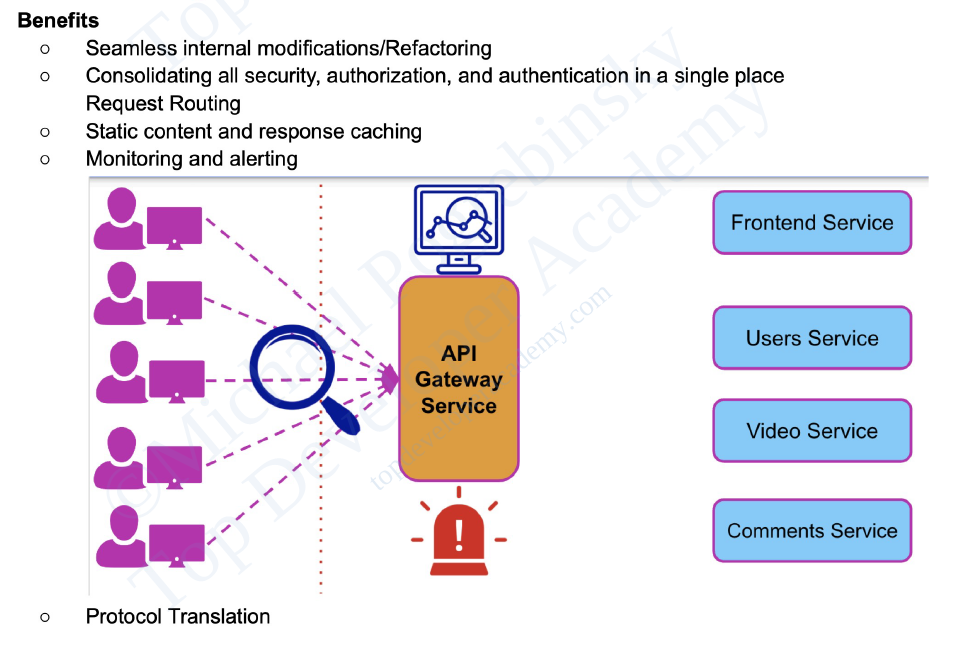
API Gateway
An API gateway is a component of
the app-delivery infrastructure that sits between clients and services and
provides centralized handling of API communication between them.

What it is
- Entry point for client requests to microservices
& services.
- Centralizes API communication, security, and
policy enforcement.
- Simplifies app delivery by decoupling internal architecture
from clients.
Key benefits
- Reduced complexity & faster app releases.
- Streamlined request processing & policy
enforcement.
- Simplified troubleshooting with granular metrics.
For microservices
- Single entry point for simplified client & service
implementations.
- Handles routing, composition, and policy
enforcement.
- Offloads non-functional requirements for faster
development.
Deployment options
- Kubernetes: Edge (Ingress controller), cluster-level
(load balancer), or within (service mesh).
- Standalone: Platform & runtime agnostic for maximum
flexibility.
Not the same as:
- Ingress Gateway/Controller: Limited capabilities, often extended with
custom resources for API gateway features.
- Kubernetes Gateway API: Standardized & improved service
networking in Kubernetes, supports fine-grained policy definitions.
- Service Mesh: Primarily for service-to-service
communication, can be a lightweight API gateway for microservices.

API Gateway vs. API
Management
- Gateway: Data-plane entry point for API calls
(request processing, routing, load balancing).
- Management: Process of deploying, documenting,
operating, and monitoring APIs (policy definition, developer portals).
Choosing an API Gateway
- Architecture: Platform, runtime, cloud provider
options.
- Performance: High throughput & low latency.
- Scalability: Vertical & horizontal scaling
for traffic demands.
- Security: Access control, mTLS, WAF, schema
validation.
- Cost: TCO comparison of custom vs. enterprise
solutions.
NGINX Options
- Kubernetes-native: NGINX Ingress Controller,
NGINX Service Mesh.
- Universal: NGINX Plus, F5 NGINX Management Suite
API Connectivity Manager.
Key Takeaways
- API gateways simplify app delivery and
microservices communication.
- Choose the right deployment option based on your
needs.
- NGINX offers various API gateway solutions for
different use cases.
Rate Limiting
Rate limiting is a technique to
limit network traffic to prevent users from exhausting system resources. Rate limiting
makes it harder for malicious actors to overburden the system and cause attacks
like Denial of Service (DoS). This involves attackers flooding a target system
with requests and consuming too much network capacity, storage, and memory.
APIs that use rate limiting can
throttle or temporarily block any client that tries to make too many API calls.
It might slow down a throttled user’s requests for a specified time or deny
them altogether. Rate limiting ensures that legitimate requests can reach the
system and access information without impacting the overall application’s
performance.
Problem: Malicious actors flood systems with
requests, causing outages and resource exhaustion.
Solution: Rate limiting throttles requests to
protect services and ensure fair access.
Benefits:
- Prevents DoS attacks: Blocks attackers from overwhelming the
system.
- Stops account takeovers: Limits bot activity and credential
stuffing.
- Saves resources: Optimizes resource usage for legitimate
requests.
How it Works:
- Tracks IP addresses and request times.
- Sets limits on requests per user/region/server in
a timeframe.
- Throttles or blocks exceeding requests.
Types of Rate Limits:
- User: Based on individual users (IP address, API
key).
- Geographic: Specific rate limits for different regions.
- Server: Different limits for different servers
within an application.
Rate Limiting Algorithms:
- Fixed-window: Allows a set number of requests within a
defined time window.
- Leaky bucket: Limits requests based on queue size, not
time.
- Sliding-window: Tracks requests within a moving time window
starting from the last request.
Why Choose Imperva:
- Comprehensive protection: Secures websites, apps, APIs, and
microservices.
- Advanced bot protection: Stops account takeovers and data scraping.
- Multiple security layers: Web Application Firewall, RASP, API
Security, DDoS Protection.
Remember: Rate limiting is a crucial security
measure for protecting your systems and ensuring optimal performance.
Heart Beat
Show a server is available by
periodically sending a message to all the other servers.
Problem
When multiple servers form a
cluster, each server is responsible for storing some portion of the data, based
on the partitioning and replication schemes used. Timely detection of server
failures is important for taking corrective actions by making some other server
responsible for handling requests for the data on a failed server.
Solution
Periodically send a request to
all the other servers indicating liveness of the sending server. Select the
request interval to be more than the network round trip time between the
servers. All the listening servers wait for the timeout interval, which is a
multiple of the request interval.
Purpose:
- Maintain connections: Prevent
idle connections from being terminated, ensuring availability for
real-time data exchange or long-running operations.
- Monitor health: Detect
inactive or unresponsive servers, enabling proactive actions to maintain
service uptime.
- Coordinate tasks: Synchronize
actions between servers or services in distributed systems.
Mechanism:
- Server sends periodic "heartbeat" signals (often simple
pings) to clients.
- Clients respond to confirm their presence and responsiveness.
- If a client fails to respond within a specified timeout, server
takes action (e.g., connection closure, recovery attempts).
Implementation:
- Transport-level heartbeats: Embedded
within network protocols (e.g., TCP Keep-Alive, WebSocket ping/pong).
- Application-level heartbeats: Custom-built
into the API logic using timers, threads, or asynchronous mechanisms.
- Third-party libraries or frameworks: Available to simplify implementation (e.g., SignalR for
ASP.NET).
Considerations:
- Frequency: Balance
overhead with responsiveness (typically every few seconds to minutes).
- Timeouts: Set appropriate thresholds to
detect failures without false positives.
- Actions: Define appropriate responses to
missed heartbeats (e.g., reconnection, failover, notifications).
- Security: Protect heartbeat signals from
unauthorized access or manipulation.
Common Use Cases:
- Long-polling for real-time updates in web applications.
- Maintaining persistent connections in chat or messaging apps.
- Monitoring server health in load-balanced environments.
- Coordinating tasks in distributed systems.
- Detecting failed services or clients in microservice architectures.
Circuit Breaker Pattern
The Circuit Breaker design
pattern is used to stop the request and response process if a service is not
working, as the name suggests. When the number of failures reaches a certain
threshold, the circuit breaker trips for a defined duration of time.

Problem: Services in microservices
architecture can fail, causing cascading failures and resource exhaustion.
Solution: Circuit Breaker pattern acts as a
proxy, protecting other services by monitoring and controlling calls to a
potentially failing service.
Benefits:
- Prevents cascading failures: Isolates the failing service, stopping it
from affecting others.
- Improves resilience: Allows the failing service to recover
without impacting other services.
- Optimizes resource usage: Limits calls to the failing service,
preventing resource exhaustion.
Key Concepts:
- States: Closed (normal operation), Open (blocks
requests), Half-Open (allows few test calls).
- Thresholds: Define failure and recovery criteria (e.g.,
number of failures, timeout).
- Fallback: Handles failed requests gracefully (e.g.,
error message, default value).
Use Cases:
- Protecting downstream services from a slow or
unresponsive service.
- Preventing overload and resource exhaustion on
the failing service.
- Implementing graceful service degradation during
outages.
Main Example:
- Mercantile Finance employee microservice with
aggregation pattern calls various backend services.
- Circuit breaker protects the aggregator and other
services from a failing backend service.
How it Works:
1.
Closed: Normal
operation, requests flow through to the service.
2.
Failure threshold reached: Circuit opens, requests fail immediately.
3.
Timeout period: Service sends test calls during this period.
4.
Test calls succeed: Circuit closes, normal operation resumes.
5.
Test calls fail: Circuit remains open, timeout restarts.
Additional Notes:
- Choose appropriate thresholds and timeouts based
on service behavior and dependencies.
- Implement monitoring and alerting for circuit
breaker states and service health.
- Consider fallback strategies for different
failure scenarios.
Remember: While some requests might fail
during an outage, the Circuit Breaker pattern prevents catastrophic system
failures and enables faster recovery.
Distributed Tracing
Distributed tracing is a tool for
understanding how requests travel through your application in complex,
cloud-native environments like microservices. Imagine it like following a
detective trail for a single user request as it winds through different services
and servers.

What it does:
- Tracks a single request (think detective
following footprints) as it interacts with various services (think
different rooms in a building).
- Tags each request with a unique identifier (think
suspect photo) so you can follow its path.
- Records details like timestamps and performance
metrics (think notes and clues) at each step.
- Connects the dots (analyzes the clues) to show
you the complete journey of the request and identify any issues.
Why it's important
- Troubleshooting: When your app runs slow or crashes,
distributed tracing helps you pinpoint the exact service causing the
problem, saving you time and frustration.
- Performance optimization: You can see where bottlenecks are slowing
down your requests and optimize your code or infrastructure accordingly.
- Better user experience: By understanding how user requests flow,
you can ensure smooth performance and avoid frustrating delays.
- Improved collaboration: Different teams working on different
services can see how their work affects the overall user experience,
enabling better communication and teamwork.
Think of it this way
- Traditional monitoring is like looking at a city
from afar – you see traffic jams but not the cause.
- Distributed tracing is like going down to street
level and following the traffic jam to its source, allowing you to fix it.
Benefits
- Reduced MTTR (mean time to repair): Faster identification and resolution of
performance issues.
- Improved SLAs: Consistent user experience and better
compliance with service-level agreements.
- Faster time to market: Quicker innovation and release cycles due
to efficient troubleshooting.
- Enhanced collaboration: Clear visibility into performance
bottlenecks fosters better communication and teamwork across teams.
Challenges:
- Manual instrumentation: Some tools require code changes, adding
complexity.
- Limited coverage: Some tools only focus on backend, omitting frontend
interactions.
- Sampling limitations: Random sampling might miss crucial traces.
When to use it
- Microservices architectures: Essential for understanding complex
interactions between services.
- Troubleshooting performance issues: Quickly identify bottlenecks and root
causes.
- Optimizing code: Proactively improve performance by
analyzing problematic microservices.
Alternatives
- Logging: Provides valuable data but lacks the
comprehensive view of distributed tracing.
- Centralized logging: Aggregates logs from multiple services, but
requires careful management.
- Distributed logging: Stores logs across the environment,
reducing network load but increasing complexity.
 |
Overall, distributed tracing
is a crucial tool for observability in modern cloud-native environments. It
empowers teams to troubleshoot issues faster, optimize performance, and deliver
a consistent, high-quality user experience.
Message Queues
Think of message queues as a line
for tasks between applications. Messages (think instructions) are sent to the
queue and wait in line until another application (the queue worker) picks them
up and completes the task. This allows applications to work independently,
without waiting for each other to finish.

What it is
- Asynchronous communication: applications send messages via a queue,
allowing independent processing.
- Temporary storage: messages wait in the queue until the
receiver is ready.
- Flexible processing: tasks are called and continue without
waiting for responses.
Basic components
- Queue: Holds messages in sequential order (like a
line).
- Message: Data (events, instructions) transported
between applications.
- Client/producer: Creates and sends messages to the queue.
- Consumer: Retrieves and processes messages from the
queue.
Benefits
- Protection against outages: queue buffers messages when the receiver is
unavailable.
- Improved performance: applications perform without waiting for
each other.
- Scalability: queues can handle high volumes of messages.
Examples: Kafka, Heron, Amazon SQS, RabbitMQ.
Design with Message
Queues
- Offline vs. in-line work: Choose based on user experience (e.g., task
scheduling vs. immediate updates).
Microservices and Message
Queues:
- Decoupling services: queues allow services to communicate
asynchronously without blocking each other.
- Message broker: acts as a "mailman" delivering
messages between services.
- Example: RabbitMQ, a popular message broker for
microservices.
Message Brokers:
- RabbitMQ:
- Components: producer, consumer, queue, exchange
(routes messages).
- Function: producer sends to exchange, exchange
routes to queues, consumer receives from subscribed queues.
- Use CloudAMQP for ease of use.
- Apache Kafka:
- More complex, ideal for high-volume streaming
data.
Choosing RabbitMQ or Kafka:
- RabbitMQ: Simpler, good for moderate workloads,
microservices.
- Kafka: Scalable, high-throughput, complex setup,
real-time streaming.
Batch Processing vs
Stream Processing
Batch processing vs. stream
processing are two different approaches to handling data. Batch processing
involves processing large volumes of data at once, at scheduled intervals. In
contrast, stream processing involves continuously processing data in real time
as it arrives.
Need-to-know concepts
- Real-time vs. scheduled processing:
- Stream processing analyzes data immediately as
it's generated, enabling instant insights and reactions.
- Batch processing handles data in predefined
chunks at scheduled intervals, offering high throughput for large
datasets but with higher latency.
- Applications:
- Stream processing is ideal for fraud detection,
real-time analytics, and live dashboards.
- Batch processing shines in ETL jobs, data
backups, and generating reports.
- Key differences:
- Latency: Stream is low-latency (real-time), batch
is high-latency (waiting for batch completion).
- Data flow: Stream handles continuous data streams,
batch deals with finite chunks.
- Complexity: Stream can be more complex due to fault
tolerance and data order issues.
- Scalability: Both can scale, but stream often
horizontally (adding more machines).
Understanding the big
data angle
- Both methods handle vast amounts of data, but the
approach differs.
- Batch processing aggregates data for deeper
analysis later, while stream processing focuses on real-time insights and
alerts.
- Choosing between them depends on the nature of
the data, desired response time, and specific business objectives.
Pros and cons
Batch processing:
- Pros: Simplified processing, high throughput,
good for deep analysis, resource-efficient, mature tools.
- Cons: Delayed insights, inflexible once started,
complex error handling, scalability challenges.
Stream processing:
- Pros: Real-time insights, flexible and adaptable,
continuous data flow, suits modern data-driven apps, horizontally
scalable.
- Cons: Complex infrastructure, potential
consistency issues, requires advanced fault tolerance, resource-intensive,
potential data order problems.
Practical examples
- Batch: Financial statements, daily data backups,
data warehouse ETL processes.
- Stream: Real-time fraud detection, social media
sentiment analysis, live analytics dashboards.
Remember: There's no one-size-fits-all
solution. Choose the best processing method based on your specific data needs
and desired outcomes.
WebSockets and Server-Sent Events
Key Considerations:
Communication Direction:
- WebSockets: Full-duplex, enabling bidirectional, real-time communication between server and client.
- SSE: Unidirectional, server-to-client only.
Data Formats:
- WebSockets: Support text and binary data.
- SSE: Limited to UTF-8 text data.
Setup Complexity:
- SSE: Simpler setup, leveraging standard HTTP infrastructure.
- WebSockets: More complex, requiring a dedicated WebSocket server or library.
Browser Compatibility:
- SSE: Supported by most modern browsers.
- WebSockets: Near-universal support, but might require fallbacks for older browsers.
Use Cases and Recommendations:
WebSockets:
- Chat apps
- Real-time collaboration tools
- Multiplayer games
- Live dashboards
- Financial trading platforms
- Interactive maps
- IoT device communication
SSE:
- Live stock tickers
- News feeds
- Sports scores
- Notification systems
- Status updates
- Social media activity streams
Additional Considerations:
- Latency: WebSockets generally offer lower latency than SSE.
- Scalability: WebSockets can handle more concurrent connections, but may require more server resources.
- Reliability: SSE has built-in reconnection mechanisms, while WebSockets may require manual handling.
- Security: Both protocols can be secured using TLS/SSL.
Best Practices:
- Clearly define communication needs: Understand whether bidirectional or unidirectional communication is required.
- Evaluate data format requirements: Determine if binary data support is necessary.
- Consider setup and maintenance overhead: Assess the complexity of implementation and management.
- Test for browser compatibility: Ensure support across target browsers.
- Plan for scaling and security: Implement measures for handling growth and protecting data.
In Conclusion:
The ideal choice depends on your specific application requirements. Prioritize WebSockets for full-duplex, real-time communication with lower latency and potential for higher scalability. Opt for SSE for simpler, unidirectional updates with less overhead and wider browser compatibility.
Caching
Think of caching as having your
favorite book readily available on your nightstand, except in the tech world,
it's copies of that book scattered across libraries globally for super-fast
access. That's distributed
caching!
The purpose of caching is to
improve the performance and efficiency of a system by reducing the amount of
time it takes to access frequently accessed data.

Benefits:
- Blazing-fast websites: Users worldwide get content from nearby
servers, not some faraway library, slashing loading times.
- Scalability galore: Add more servers as your users and data
grow, keeping everyone happily served.
- Always online: Even if one server stumbles, others pick up
the slack, ensuring continuous service.
- Cost-effective champion: Reduce database load and bandwidth usage,
saving you precious resources.
How it works:
- Data spread across servers: Your book copies (data) are placed on
servers closer to users in different regions.
- Requests fly to the nearest: Users ask for data, and it zooms from the
closest server, like grabbing your book from the nearby library.
- Smart data distribution: Special algorithms ensure data is evenly
spread and efficiently retrieved.
- Always fresh and reliable: Copies are kept up-to-date so you always
get the latest edition (data).
Remember:
- Choose the right solution: Redis, Memcached, Hazelcast, and more, each
caters to different needs.
- Keep data consistent: Make sure all copies match the original
source.
- Monitor and fine-tune: Optimize your distributed cache for maximum
performance and efficiency.
Cache Invalidation
If the data is modified in the
database, it should be invalidated in the cache, if not, this can cause
inconsistent application behaviour.
Cache Eviction Policies
Following are some of the most
common cache eviction policies:
- First In First Out (FIFO): The cache evicts the first block accessed
first without any regard to how often or how many times it was accessed
before.
- Last In First Out (LIFO): The cache evicts the block accessed most
recently first without any regard to how often or how many times it was
accessed before.
- Least Recently Used (LRU): Discards the least recently used items
first.
- Most Recently Used (MRU): Discards, in contrast to LRU, the most
recently used items first.
- Least Frequently Used (LFU): Counts how often an item is needed. Those
that are used least often are discarded first.
- Random Replacement (RR): Randomly selects a candidate item and
discards it to make space when necessary.
Caching Patterns
If the data is modified in the
database, it should be invalidated in the cache, if not, this can cause
inconsistent application behavior. There are majorly five patterns to
turbocharge your application's data access:
Cache Aside (Lazy
Loading)
Cache Aside, also known as Lazy
Loading, is a simple yet powerful caching pattern for storing frequently
accessed data.

Here's how it works:
1.
Application checks the cache: Your application first tries to find
the data you need in the cache. Think of it as peeking on your bookshelf for
your favourite book.
2.
Cache hit? You're golden! If the data is there (a "cache hit"),
you're all set! The application grabs it from the cache and sends it right back
to you, offering super-fast access.
3.
Cache miss, no worries: If the data isn't in the cache (a "cache
miss"), no big deal! The application simply retrieves it from the original
data source, like fetching your book from the library.
4.
Cache it for later: Once the data is retrieved, the application stores a copy in
the cache for future requests. That's like adding your borrowed book to your
own shelf for quick future reads.
5.
Next time, straight from the shelf: For subsequent requests for the same
data, the application can skip the library trip and grab it directly from the
cache, making your future access lightning-fast!
Benefits:
- Simple to implement: Easy to understand and integrate into your
application.
- Efficiently caches data: Only stores what's actually used, avoiding
cluttering the cache.
- Offers good performance: Delivers fast access for frequently
requested data.
Drawbacks:
- Potential for stale data: The cached data might become outdated if
the source gets updated later.
- Degraded latency on first request: The initial data retrieval can be slower
than subsequent cached reads.
Overall, Cache Aside is a
versatile and popular pattern for general-purpose caching, especially in
read-heavy scenarios. It's like having a well-stocked personal library for your
most-needed books, offering quick access and convenience!
Write Through
In Write Through caching, imagine
your favourite book is so precious that you update both your personal copy and
the library version simultaneously! That's the essence of this pattern:

1.
Application writes to the cache: Whenever your application writes new
data, it first updates the cached copy, just like putting the new edition on
your bookshelf.
2.
Cache talks to the database: But unlike you, the cache doesn't
keep secrets! It immediately sends the updated data to the original data
source, like handing the new book to the librarian.
3.
Database updated, all in sync: Once the database receives the data,
it gets written there too, ensuring both the cache and the source have the
latest version.
4.
Application gets confirmation: After successfully updating both
sides, the cache sends a confirmation back to the application, like a satisfied
nod from the librarian.
Benefits:
- Data consistency guaranteed: No stale data worries, because both cache
and database always have the same information.
- Fast read access: Cached data stays fresh, resulting in quick
retrieval for subsequent reads.
Drawbacks:
- Slower writes: Updating both cache and database adds an
extra step, meaning writes take longer compared to other patterns.
- Potentially unnecessary cache updates: If most cached data isn't frequently read,
writing it to the database might be an unnecessary performance overhead.
Overall, Write Through is
ideal for situations where data consistency is crucial and you expect
relatively few writes compared to reads. It ensures your personal book and the
library copy always match, keeping everyone in the loop!
Read Through
Imagine you're at your friend's
library, looking for a book you haven't borrowed before. Read Through caching
works like this:

1.
Application checks the cache: You first peek at your friend's
bookshelf (the cache) for the book (data).
2.
Cache miss? Ask the librarian (database): If the book isn't there, you
politely ask the librarian (the database) to find it.
3.
Librarian hands you the book: The librarian retrieves the book
(data) from their collection and gives it to you.
4.
Your friend adds a copy to their shelf: Your friend, seeing you enjoy the
book, makes a copy and adds it to their bookshelf (the cache) for future
guests.
5.
Next time, straight from the shelf: If you return for another read, the
book is now conveniently on your friend's shelf (the cache), offering quicker
access.
Benefits:
- Low read latency for frequently accessed
data: Cached data
speeds up subsequent requests.
- Improved read scalability: Handles high read loads efficiently by
reducing database trips.
Drawbacks:
- Potential data inconsistency: The cached copy might become outdated if
the data source is updated later.
- High latency on a cache miss: The initial data retrieval can be slower
than subsequent cached reads.
Overall, Read Through is
great for read-heavy workloads where data freshness isn't critical and a high
cache miss rate is acceptable. It's like borrowing a book from a friend who
updates their library regularly, offering convenience for most reads.
Write Back
Imagine you have a super-fast
personal library with a lazy librarian. That's the essence of Write Back
caching:

1.
Application writes to the cache: When you add a new book, you place
it on your bookshelf (the cache) first.
2.
Cache takes a nap: The librarian (cache) decides to relax for a bit and doesn't
immediately update the library's collection (the database).
3.
Application gets a quick confirmation: You get a swift nod saying the book
is "added," even though it's only in your personal library for now.
4.
Cache catches up later (asynchronously): Eventually, the librarian wakes up,
grabs the new books from your shelf, and updates the library's records,
ensuring everyone else can find them too.
Benefits:
- Fast writes: Updates are nearly instant, as you only
need to update the cache.
- Improved performance: Batching writes to the database can reduce
overall load and optimize performance.
Drawbacks:
- Risk of data loss: If the cache fails before updating the
database, those precious new books might disappear!
- Complex implementation: Managing asynchronous updates and potential
inconsistencies requires careful design.
Overall, Write Back is ideal
for write-heavy workloads where speed is crucial, and data durability isn't the
top priority. It's like having a speedy personal library with an occasional
nap-loving librarian—great for fast additions, but make sure to back up your
cache!
Write Around
Write Around caching, like a
secret library hidden deep within an ancient castle, prioritizes data security
and minimizes unnecessary traffic.

Here's how it works:
1.
Application writes directly to the source: Imagine you sneak past the guards
and scribble on your hidden parchment within the castle vaults (the database).
You bypass the public library (the cache) entirely.
2.
Only access the cache for reads: When you need to reference the
information, you venture back to the vaults (the database) again, ignoring the
library altogether.
3.
Cache stays untouched, unless...: Only if you find yourself repeatedly
visiting the same vault location (frequently accessing the same data), do you
consider copying that parchment onto a readily accessible shelf in the library
(caching the data).
Benefits:
- Reduced risk of data loss: Updates happen directly in the source,
eliminating the chance of cache failures compromising data.
- Reduced cache pollution: No unnecessary data fills the cache,
keeping it lean and efficient for frequently accessed items.
Drawbacks:
- High read latency: Initial data access requires trips to the
source, making initial reads slower than cached scenarios.
- High cache miss rate: The cache is less utilized, leading to more
database hits.
Overall, Write Around excels
in situations where data security and minimizing unnecessary updates are
critical, even if it means sacrificing initial read speed. Think of it as a
secure, hidden library for your most valuable information, accessed only when
absolutely necessary.
Remember, Write Around isn't the
fastest pattern, but it prioritizes data integrity and efficiency for specific
scenarios.
Summary
·
Cache Aside (Lazy Loading): Easiest to implement, caches accessed data only,
ideal for general needs and read-heavy workloads.
·
Write Through: Ensures data consistency but slows down writes; good for few
writes where fresh data matters.
·
Read Through: Low read latency for frequent reads, but potential
inconsistency; okay for high cache miss rate scenarios.
·
Write Back: Fast writes, batch updates, but risky if cache fails;
perfect for write-heavy workloads where durability isn't crucial.
·
Write Around: Minimizes data loss and pollution, but suffers high read
latency; ideal for rare updates and reads.
Remember: Combine patterns, choose wisely
based on needs, and watch your data fly!
Distributed Caching
Distributed caching stores
frequently used data across multiple servers, like having copies of your favourite
book in libraries worldwide. This makes data access faster and more reliable, especially for geographically distributed applications.

Benefits:
- Scalability: Add more servers as your data grows,
keeping everyone served seamlessly.
- Fault tolerance: Server failures won't disrupt service; data
is available elsewhere.
- Performance: Data is closer to users, leading to faster
response times.
- Cost-effectiveness: Reduces database load and bandwidth usage.
Key components:
- Cache servers: Store data across multiple nodes for
efficient access.
- Partitioning: Divides data across servers for balanced
distribution and retrieval.
- Replication: Backs up data on multiple servers for high
availability.
Popular solutions:
- Redis: Versatile, high-performance cache,
database, and message broker.
- Memcached: Simple, powerful cache for dynamic web
applications.
- Hazelcast: Offers caching, messaging, and computing
for cloud-native apps.
- Apache Ignite: In-memory computing platform with
distributed caching, data processing, and transactions.
Implementation and best
practices:
- Choose the right solution: Consider your application needs and
infrastructure.
- Configure and deploy: Install software on servers and define data
strategies.
- Integrate with application: Direct data reads and writes to the cache.
- Monitor and fine-tune: Adjust configurations for optimal
performance.
- Manage cache effectively: Use eviction policies and monitor hit/miss
rates.
Remember: Distributed caching is a powerful
tool to boost your application's performance, scalability, and user experience.
Choose the right solution, manage it effectively, and watch your data access
fly!
Content Delivery Network
(CDN)
Tired of slow-loading websites? A
CDN's your answer! It's a network of geographically distributed group of
servers that caches content close to end users. A CDN allows for the quick
transfer of assets needed for loading Internet content, including HTML pages,
JavaScript files, stylesheets, images, and videos.

There are two main strategies used by CDNs to deliver content: Pull and Push.
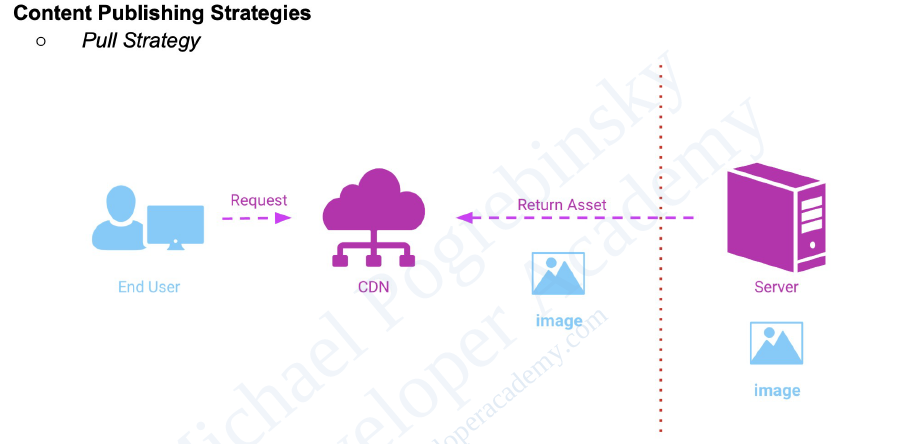
Pull CDN:
- In a Pull CDN, the cache is updated based on request. When the client sends a request that requires static assets to be fetched from the CDN, if the CDN doesn’t have it, then it will fetch the newly updated assets from the origin server and populate its cache with this new asset, and then send this new cached asset to the user.
- This requires less maintenance because cache updates on CDN nodes are performed based on requests from the client to the origin server.
- The main advantage of Pull CDN is that unlike the Push CDN the PoP servers here in this case do all the heavy lifting, while our engineers can just relax and not be too exhausted from maintaining all the push operations.
- However, this also comes with some disadvantages, if a request to a particular CDN is updating the cache from the origin server to respond to a client, and the same query is re-queried to the same CDN node, this could cause redundant traffic.
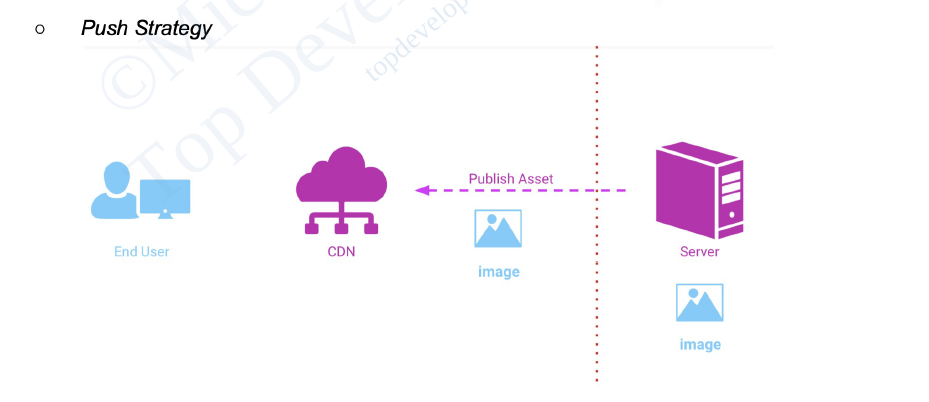
Push CDN:
- In a Push CDN, the assets have to be pushed to the servers. It is the responsibility of the engineers to push the assets to the origin server which will then propagate to other CDN nodes across the network.
- The assets that are received through propagation are then cached onto these CDN servers such that when a client sends a request the CDN provides this cached asset.
- While configuring and setting up a Push CDN takes longer, it is far more flexible and precise when it comes to providing the appropriate material at the right moment.
- If by any chance the engineers don’t update the assets to the origin servers consistently without fail, then the user may receive stale data.
In general, Pull CDN is the preferred method for websites that get a lot of traffic because content remains relatively stable, and the traffic is pretty spread out. If you have a minimal amount of traffic, you might prefer Push CDN because content is pushed to the server once, then left there until changes are needed.
Benefits:
- Faster websites: Keep visitors happy with speedy loading
times.
- Lower costs: Reduce bandwidth expenses with efficient
data caching.
- High availability: Never worry about downtime thanks to
redundancy and failover.
- Enhanced security: Protect your site from attacks with
advanced security features.
How it works:
- Servers placed near users, reducing travel time
for content.
- Optimizations like compression and smart routing
speed things up.
- Redundancy ensures your site stays online, even
if some servers go down.
ACID Transactions
ACID stands for Atomicity,
Consistency, Isolation, and Durability. These are four key properties that
ensure reliable and consistent data handling in databases. Imagine them as
safety nets for your data:

- Atomicity: Either all parts of a transaction succeed,
or none do. No half-finished updates!
- Consistency: Data remains valid before and after each
transaction. Think of it as keeping the books balanced.
- Isolation: Transactions don't interfere with each
other. One transaction's update won't affect another until it's complete.
- Durability: Once committed, changes persist even if the
system crashes. Consider it as writing in ink, not pencil.
Benefits
- Data integrity: ACID protects your data from
inconsistencies and corruption.
- Reliability: Even with failures, transactions ensure
updates are correct and completed.
- Consistency: Data always maintains its logical rules and
constraints.
Trade-offs
- Overhead: ACID features add processing steps,
potentially impacting performance.
- Deadlocks: Concurrent transactions waiting for each
other can freeze up the system.
- Scalability: ACID can be challenging to implement in
large, distributed systems.
Alternatives
- BASE: Emphasizes availability over immediate
consistency, suitable for high-volume systems.
- CAP theorem: Explains trade-offs between consistency,
availability, and partition tolerance.
- NoSQL databases: Prioritize scalability and performance over
strict ACID guarantees.
When to use ACID
- Banking, healthcare, e-commerce: Crucial for
accurate and secure financial transactions, patient records, and order
processing.
- Mission-critical applications: Where data
integrity and reliability are paramount.
Remember: ACID isn't always the best fit.
Evaluate your needs and consider alternatives like BASE for more flexible
approaches in specific scenarios.
CAP Theorem
Imagine a distributed database:
data scattered across different servers. Network failure strikes! Can you
access all your data (availability) or ensure it's always up-to-date
(consistency)? The distributed system with replicated data can only offer two out
of three: Consistency, Availability, and Partition Tolerance (dealing with
network hiccups). So, you gotta choose!

CAP Theorem says: pick two!
- Consistency: Latest data guaranteed, but might be
unavailable during errors. (Think accurate bank balance.)

- Availability: Always accessible, but data might be
outdated. (Think online shopping during peak hours.)
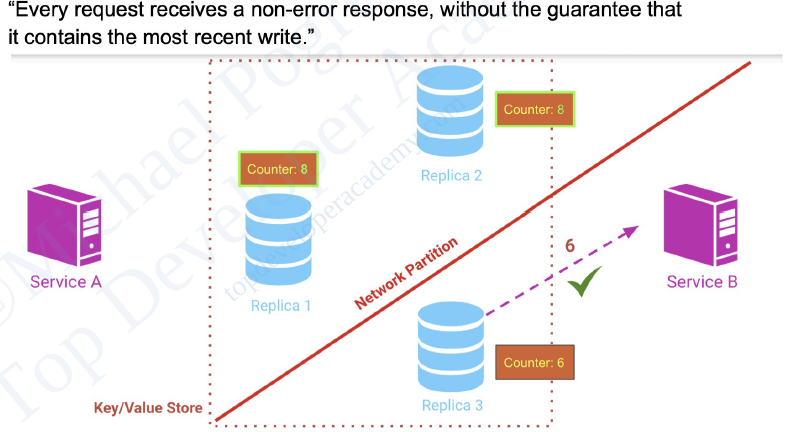
- Partition Tolerance: Must-have for distributed systems – handles
network issues.
Think of it as a recipe: high
consistency comes with a dash of reduced availability, and vice versa.
Choosing your flavour:
- SQL databases: Prioritize consistency for accurate data
(think finances).
- NoSQL databases: Offer high availability for always-on
services (think online shopping).
So, next time you design a
system, remember the CAP Theorem – it's the secret ingredient that keeps your
data dancing between consistency and availability.
Data Replication
Data replication also known as
database replication, is a method of copying data to ensure that all
information stays identical in real-time between all data resources.
Data replication is like a safety
net for your information, ensuring identical copies across multiple locations.
Think of it as a real-time mirror for your data, constantly reflecting updates,
whether across on-prem servers or to the cloud.

Why is it important?
- Instantaneous updates: Say goodbye to refresh buttons and lag.
Data replication keeps everyone in sync, boosting user experience and
productivity.
- Disaster recovery: If your primary server fails, a replica
seamlessly takes over, minimizing downtime and protecting critical data.
- Performance boost: Spread the workload across multiple
instances for faster reads and writes, especially with data geographically
distributed.
- Reduced IT effort: Automate data replication and focus on more
strategic tasks.
Types of Replication
- Full vs. Partial: Full replicates everything, while partial
focuses on specific data, like financial data in a specific office.
- Transactional: Real-time mirroring of changes, ideal for
consistency but demanding on resources.
- Snapshot: Captures data at a specific point, useful
for backups and recoveries.
- Merge: Allows independent edits on each node, then
merges them all.
- Key-Based: Efficiently updates only changed data but
doesn't replicate deletions.
- Active-Active Geo-Distribution: Real-time, global data syncing for
geographically dispersed centers.
Synchronous vs.
Asynchronous Replication
- Synchronous: Writes happen on both primary and replica
simultaneously, maximizing consistency but impacting performance.
- Asynchronous: Writes on primary first, copied to replica
later, faster but prone to data loss in case of failure.
Challenges to Consider
- Cost: Maintaining multiple instances requires
significant resources.
- Expertise: Skilled professionals are needed to manage
and troubleshoot.
- Network bandwidth: Heavy replication traffic can overload
networks.
Data Redundancy
Data redundancy is when multiple
copies of the same information are stored in more than one place at a time on same system.
This can be helpful for backups and security, but it can also cause problems
like increased storage costs, errors, and inaccurate data.

How it happens
Unintentional redundancy can
occur through various ways, like duplicate forms, multiple backups, or outdated
versions.
Types
- Database vs. File-based: Redundancy can happen in both, but
structured databases typically offer better control.
- Data replication vs. redundancy: Replication is intentional (for
accessibility), while redundancy can be intentional or unintentional.
Benefits
- Backups: Provides extra copies in case of data loss.
- Disaster recovery: Ensures quick restoration after system
failures.
- Data accuracy: Enables cross-checking for discrepancies.
- Improved data protection: Minimizes attack surface and data access
points.
- Increased availability: Makes data accessible from multiple
locations.
- Business continuity: Protects against data loss from internal
issues or malware.
Disadvantages
- Data corruption: Errors during storage or transfer can
corrupt copies.
- Increased maintenance costs: Requires managing multiple copies.
- Data discrepancies: Updates may not be applied to all copies.
- Slow performance: Database functions can be hindered.
- Storage waste: Duplicate data takes up unnecessary space.
Reducing redundancy
- Delete unused data: Implement data lifecycle rules and
monitoring.
- Design efficient databases: Use common fields and architectures.
- Set goals and plans: Aim for reduction, not complete
elimination.
- Use data management systems: Identify and address redundancy issues.
- Implement master data strategy: Integrate data from various sources for
better management and quality.
- Standardize data: Makes redundancy and errors easier to
detect.
Remember: Data redundancy can be both friend
and foe. Use it strategically for backups and security, but actively manage it
to avoid the pitfalls.
Database Scaling
When your application becomes
popular, it needs to scale to meet the demand. Nobody sticks around if an
application is slow — not willingly, anyway.

Scaling Approaches
- Vertical Scaling: Increase resources on one node (like
upgrading your computer). Simple, but limited growth.
- Horizontal Scaling: Add more nodes to share the workload (like
adding more computers). More complex, but scales further.
Horizontal Scaling
Techniques
- Sharding: Split data across multiple nodes. Easy to
implement, but requires managing the shard selector and can have imbalance
issues.
- Read Replicas: Dedicated nodes for read requests,
improving read performance without affecting writes. Simple and improves
availability, but doesn't improve write performance.
- Active-Active: All nodes handle both reads and writes,
maximizing performance. Most complex, requires conflict resolution logic
in your application.
- Active-Active Geo-Distribution: Active-Active across geographically
distributed clusters, for global reach and improved latency. Advanced
solution, managed by Redis Enterprise.
Choosing the Right Option
- Consider your performance needs, data size, budget, and
technical expertise.
- Start with simple options like vertical scaling or read replicas if
complexity is a concern.
- Sharding and Active-Active offer more scalability, but require careful
planning and implementation.
- Active-Active Geo-Distribution is for global deployments with high
demands.
Remember: Scaling is a powerful tool, but
choose wisely based on your specific needs and capabilities.
Database Sharding
Your database is struggling
under the weight of your application's rapid growth. More users, features, and data mean
bottlenecks and slow performance. Sharding might be the answer, but understanding its pros, cons, and use cases is crucial
before diving in.
What is Database
Sharding?
Sharding splits your database
across multiple servers, distributing the data load and increasing capacity.
Imagine slicing a pizza: each shard (slice) holds a portion of the data, spread
across different servers.
 |
Do You Need Sharding?
Consider alternatives before
sharding:
- Vertical scaling: Upgrade your existing server's hardware
like RAM or CPU.
- Specialized services: Offload specific tasks like file storage or
analytics to dedicated services.
- Replication: Make read-heavy data available on multiple
servers for faster access.
When Sharding Shines
- High read/write volume: Sharding handles both reads and writes
effectively, especially when confined to specific shards.
- Large storage needs: Increase total storage capacity by adding
more shards as needed.
- High availability: Replica sets within each shard ensure data
remains accessible even if a shard fails.
The Downsides of Sharding
- Query overhead: Routing queries across shards adds latency,
especially for queries spanning multiple shards.
- Administrative complexity: Managing multiple servers and shard
distribution increases upkeep requirements.
- Infrastructure costs: Sharding requires more computing power,
pushing up expenses.
How Does Sharding Work?

- Data distribution: Define how data is spread across shards.
Popular methods include range-based (data ranges assigned to shards),
hashed (hash function determines shard), and entity/relationship-based
(keeps related data together).
- Query routing: Determine how queries are routed to the
appropriate shards.
- Shard maintenance: Plan for redistributing data and adding new
shards over time.
Sharding Architectures
- Ranged/dynamic sharding: Easy to understand, relies on a suitable
shard key and well-defined ranges.
- Algorithmic/hashed sharding: Evenly distributes data but may require
rebalancing and hinder multi-record queries.
- Entity-/relationship-based sharding: Improves performance for related data
access but can limit flexibility.
- Geography-based sharding: Ideal for geographically distributed data,
improves performance and reduces latency.
Remember: Sharding is a powerful tool for
large applications with demanding data needs. But weigh the complexity and
costs against alternative solutions before making the leap. Choose the right
sharding architecture based on your specific data distribution and query
patterns.
SQL vs NoSQL
Choosing the right database
architecture: When
building applications, one of the biggest decisions is picking between
structured (SQL) and unstructured (NoSQL) data storage. Both have unique
strengths and cater to different needs, making this choice crucial for optimal
data management.

Key Differences
- Structure: SQL uses rigid tables and predefined
schemas, while NoSQL offers flexible document-based or key-value
structures.
- Queries: SQL excels at complex relational queries,
while NoSQL focuses on simple key-based lookups or document searches.
- Scalability: SQL scales vertically (adding more power to
a single server), while NoSQL scales horizontally (adding more servers to
the network).
- Transactions: SQL guarantees ACID properties (Atomicity,
Consistency, Isolation, Durability) for data integrity, while NoSQL may
not.
When to use SQL
- Structured data: When data has a predefined schema and
relationships between tables are well-defined.
- Complex queries: When your application needs to perform
complex joins and analysis across multiple tables.
- Transactions: When data integrity is critical, and ACID
properties are essential.
When to use NoSQL
- Unstructured data: When data is dynamic, semi-structured, or
constantly evolving.
- High performance: When your application needs fast responses
and high scalability for large datasets.
- Simple queries: When basic lookups and document searches
are sufficient for your needs.
Popular Databases
- SQL: MySQL, PostgreSQL, Oracle, Microsoft SQL
Server
- NoSQL: MongoDB, Cassandra, Redis, Couchbase,
DynamoDB
NewSQL: a hybrid approach combining SQL’s
ACID guarantees with NoSQL’s scalability. Useful for applications needing both
features.
Remember: There's no one-size-fits-all
solution. Analyze your data and application needs to choose the best fit.
Database Indexes
An index is a database structure
that you can use to improve the performance of database activity. A database
table can have one or more indexes associated with it.

What are indexes?
- Database structures for faster record retrieval.
- Think of them as bookmarks in a book, quickly
directing you to specific pages.
Benefits
- Boosts search speed: Especially for large tables.
- Improves select queries: Particularly effective for conditions
matching the index expression.
Trade-offs
- Slower inserts/updates/deletes: Maintaining indexes adds processing overhead.
- Increased disk space: Indexes consume additional storage.
Choosing the right
indexes
- Consider how you use the table: More retrievals? Create indexes for search
criteria.
- One field queries: Simple indexes on individual fields.
- Multi-field queries: Concatenated indexes for frequently
combined conditions.
- AND vs. OR: Indexes work well for AND conditions, not
OR.
Tips for optimal indexing
- Match index expression to selection
conditions.
- Use concatenated indexes for frequent
multi-field searches.
- Prioritize AND conditions over OR in the
Where clause.
Joins & indexes
- Indexes on second table's join field
significantly improve performance.
- Create indexes on join fields for subsequent
tables in the From clause.
Remember:
- Indexes aren't a magic bullet. Analyze your
database usage and create indexes strategically.
- Too many indexes can be counterproductive. Find
the balance for optimal performance.
Strong vs Eventual
Consistency
Imagine your laptop notes
like data in a distributed system.

- Master-Slave: This is like copying your notes to an external drive.
Both versions are consistent, but updating the drive takes time. You might
read stale notes if it hasn't been updated recently.
- Eventual: Think of this as sending your notes to Dropbox.
Updates happen eventually, but not instantly. Reading before an update
reaches Dropbox could give you outdated information.
- Strong: This is like typing directly on your notes in Dropbox.
Updates are immediate and everyone sees the latest version. But writing
takes longer as Dropbox syncs with all devices.
Choosing the right model
depends on your needs
- High availability: Eventual wins for fast reads and uptime,
even if data might be stale sometimes.
- Data consistency: Strong guarantees the freshest data, but
reading/writing might be slower.
- Simple application logic: Strong keeps things predictable, but
eventual can be easier to manage.

Remember: Each model has its trade-offs.
Choose the one that best balances your needs for availability, consistency, and
performance.
Bonus: Linearizability and Causal
Consistency are stricter cousins of Strong and Eventual, respectively. They
offer finer control over data ordering for specific situations.
Fault Tolerance
Fault tolerance describes a
system's ability to handle errors and outages without significant disruption.
Think of it as a system's backup plan when things go wrong.
Why is it important?
Uptime is crucial for
mission-critical applications. High availability, achieved through fault
tolerance, minimizes downtime and keeps your system running smoothly even
during hiccups.
Key concepts
- Multiple hardware/software: Redundancy is key. Having backups for
servers, databases, and software instances ensures continuity during
failures.
- Backup power: Generators and failover systems protect
against power outages.
- Graceful degradation: Some outages might result in reduced
functionality, but the system remains mostly operational.
- Survival goals: Define how much the system should handle,
from single node failures to entire cloud region outages.
- Cost vs. impact: Weigh the cost of fault-tolerant setups
against potential losses from downtime.
Real-world example
A major electronics company
needed a scalable, fault-tolerant database. Manually sharding MySQL seemed
complex and expensive. Migrating to CockroachDB, a managed, inherently
fault-tolerant database, reduced manual tasks and saved millions in labor
costs.

Different fault tolerance
approaches
- Cloud-based, multi-region architecture: Microservices running in Kubernetes
clusters across regions provide high availability for both application and
database layers.
- CockroachDB: This distributed SQL database offers
inherent fault tolerance and scales horizontally, eliminating the need for
manual sharding.
Remember: Fault tolerance is a spectrum.
Choose the level that suits your needs and budget, aiming for minimal
disruption and maximum user experience.
Network Protocols
The network protocols are like
the traffic laws of computer networks. They define how devices communicate,
ensuring orderly and efficient data exchange.

Here's a focused look at two key
layers and their primary protocols:
- Application Layer (Layer 7): Manages specific application tasks and data
interactions.
- Transport Layer (Layer 4): Manages data delivery and reliability
between applications.
Application Layer (Layer
7)
- HTTP: Web content transfer
- HTTPS: Secure HTTP with encryption
- FTP: File transfers
- SMTP: Email
- DNS: Domain name resolution
- WebSockets: Full-duplex, real-time communication
between web browsers and servers
- WebRTC: Peer-to-peer audio/video communication and
data exchange
Transport Layer (Layer 4)
- TCP: Reliable, connection-oriented delivery
(like sending a tracked package)
- Used by HTTP, HTTPS, WebSockets, WebRTC, and
many others for guaranteed delivery.
- UDP: Unreliable, connectionless, faster but
lossy (like sending a postcard)
- Used for real-time applications (streaming,
gaming) where some loss is acceptable.
Key Considerations for System
Design:
- Application Needs: Match protocols to specific requirements
(e.g., WebSockets for chat, WebRTC for video calls, TCP for file
transfers, UDP for real-time gaming).
- Network Conditions: Consider bandwidth, latency, and
reliability.
- Security: Implement appropriate measures based on
protocol vulnerabilities.
- Interoperability: Ensure compatibility between devices and
systems.
- Reliability vs. Speed: TCP for critical data, UDP for real-time
applications where some loss is acceptable.
- Latency: WebRTC often offers lower latency than
WebSockets.
- Scalability: WebSockets excel in scalability for
server-client communication.
Proxy Server
A proxy server is a system or
router that provides a gateway between users and the internet. Therefore, it
helps prevent cyber attackers from entering a private network. It is a server,
referred to as an “intermediary” because it goes between end-users and the web
pages they visit online.

What it is
- Gateway between users and the internet.
- Protects private networks from cyberattacks.
- Acts as an intermediary for web requests.
Benefits
- Enhanced security: Acts as a firewall, hiding your IP address.
- Privacy: Browse, watch, and listen privately.
- Location access: Bypass geo-restrictions.
- Content control: Block unwanted websites for employees.
- Bandwidth saving: Cache files and compress traffic.
Types
- Forward: Single point of entry for internal
networks.
- Transparent: Undetectable, seamless user experience.
- Anonymous: Hides identity and computer information.
- High anonymity: Further erases information before
connection.
- Distorting: Hides its own identity while showing a fake
location.
- Data center: Fast and inexpensive, but not highly
anonymous.
- Residential: Uses real, physical devices for increased
trust.
- Public: Free but slow and potentially risky.
- Shared: Affordable but prone to misuse by others.
- SSL: Provides encrypted communication for
enhanced security.
- Rotating: Assigns different IP addresses for
anonymity and web scraping.
- Reverse: Forwards requests to web servers and
balances load.
How it works
1.
User
sends request to proxy.
2.
Proxy
forwards request to website.
3.
Website
sends response to proxy.
4.
Proxy
forwards response to user.
Choosing a proxy
- Consider your needs: security, privacy, location,
etc.
- Compare different types and providers.
- Balance cost and performance.
Remember: Public proxies are risky, prioritize
trusted providers.
Latency vs Throughput
Latency and throughput are two
metrics that measure the performance of a computer network. Latency is the
delay in network communication. It shows the time that data takes to transfer
across the network. Networks with a longer delay or lag have high latency,
while those with fast response times have lower latency. In contrast,
throughput refers to the average volume of data that can actually pass through
the network over a specific time. It indicates the number of data packets that
arrive at their destinations successfully and the data packet loss. In other words, how much data a server can process within a given time frame. If server is able to process more data in than server has heigh throughput else low throughput.

Network Performance: Key
Metrics Explained
Three vital measures:
- Latency: Delay in data transfer, impacting response
times (low = fast, high = slow).
- Throughput: Volume of data transferred over time,
indicating capacity (high = handles lots of data, low = easily
overloaded).
- Bandwidth: Bandwidth refers to the amount of data that
can be transmitted and received during a specific period of time.
Why they matter:
- Speed: Determine overall network speed and user
experience.
- Efficiency: Low latency ensures responsiveness, high
throughput supports many users.
- Impact: High performance boosts revenue and
operational efficiency.
Measuring them:
- Latency: Ping time (round-trip) in milliseconds
(lower = better).
- Throughput: Network testing tools or manual
calculations (divide file size by transfer time).
Units:
- Latency: Milliseconds (ms).
- Throughput: Bits per second (bps), kilobytes per second
(KBps), megabytes per second (MBps), gigabytes per second (GBps).
- Bandwidth: Bits per second (bps), kilobytes per second
(KBps), megabytes per second (MBps), gigabytes per second (GBps).

Bandwidth vs Throughput
While throughput and bandwidth
may seem similar, there are some notable differences between them. If bandwidth
is the pipe, then throughput is the water running through the pipe. The bigger
the pipe, the higher the bandwidth, which means a greater amount of water can
move through at any given time.
In a network, bandwidth
availability determines the number of data packets that can be transmitted and
received during a specific time period, while throughput informs you of the
number of packets actually sent and received.
Influencing factors:
- Latency: Location, congestion, protocols, network
infrastructure.
- Throughput: Bandwidth, processing power, packet loss,
network topology.
Relationship:
- Both work together for optimal performance.
- Bandwidth sets the upper limit for throughput.
- Low latency improves efficiency even with limited
bandwidth.
Takeaway: Understand and optimize latency and throughput
for a responsive, efficient network that supports your needs.
Failover
Failover is the ability to
seamlessly and automatically switch to a reliable backup system. Either
redundancy or moving into a standby operational mode when a primary system
component fails should achieve failover and reduce or eliminate negative user
impact.
What it is
- Automatic switch to a backup system when the
primary fails.
- Reduces downtime and protects against disasters.
- Achieved through redundancy or standby systems.
Types
- Failover: Automatic, triggered by heartbeat signals.
- Switchover: Manual intervention needed.
- Clusters: Groups of servers for continuous
availability.
Benefits
- Minimal downtime: Services stay online during failures.
- Data protection: Prevents data loss in case of outages.
- Improved reliability: Systems remain operational most of the
time.
Configurations
- Active-Active: Both servers active, load balanced.
- Active-Standby: One server active, one on standby.
Common Failovers
- SQL Server: Redundant servers and shared storage.
- DHCP: Multiple servers share IP address
assignment.
- DNS: Backup IP addresses for server redirection.
- Application Server: Separate servers with load balancing.
Important details
- Failover testing validates system recovery
capabilities.
- Secure communication crucial for failover
partners.
- VMware NSX offers high availability clusters for
load balancers.
Gossip Protocol
Gossip protocol is like the
grapevine for your computer network, spreading information quickly and
efficiently like rumors through small towns. Here's the lowdown:
What it does:
- Imagine messages hopping from node to node in
your network, whispering the latest news to each other.
- Each node randomly picks a few neighbors and
shares the messages it knows.
- These neighbors repeat the process, spreading the
messages further like ripples in a pond.
- Eventually, everyone in the network gets the
news, even if it takes a few whispers.
Why it's useful:
- Fast updates: Information spreads quickly without a
central hub, keeping everyone in the loop.
- Resilient to failures: Even if some nodes go down, the gossip
continues through other paths.
- Scalable: Works well for large networks with many
nodes, just like gossip thrives in big communities.
- Simple to implement: No complex infrastructure needed, just
nodes talking to each other.
Real-world examples:
- Service discovery: Nodes learn about each other's availability
and capabilities.
- Data replication: Updates reach all nodes, keeping everyone's
data consistent.
- Distributed consensus: Nodes agree on a common state even without
a central authority.
Challenges to consider:
- False rumors: Inaccuracy can spread alongside rumors,
requiring verification mechanisms.
- Overload: Too much gossip can overwhelm nodes,
affecting network performance.
- Inefficiency: Redundant transmissions can occur,
especially in dense networks.
Overall, gossip protocol is a
powerful tool for information dissemination in decentralized networks, offering
speed, resilience, and scalability with inherent challenges to manage.
Domain Name System (DNS)
Ever wondered how you type in a
website address like "nytimes.com" and instantly see the news? It's
all thanks to a hidden world of servers called the Domain Name System (DNS), the phonebook of the internet.

Imagine DNS as a librarian: you ask for a book (website), the
librarian (resolver) checks the catalog (root nameservers), finds the section
(TLD servers), locates the shelf (domain nameserver), and grabs the book (IP
address). This address then tells your computer where to find the website's
data.
Here's the behind-the-scenes
magic:

- 8 Steps to Web Magic:
1.
You
type "nytimes.com".
2.
Your
computer asks a DNS resolver (librarian)
for the address.
3.
The
resolver checks the root nameserver (catalog)
for the ".com" section.
4.
The
root nameserver points to the TLD server (.com).
5.
The
TLD server points to the domain nameserver (shelf)
for "nytimes.com".
6.
The
domain nameserver gives the IP address (book)
to the resolver.
7.
The
resolver sends the IP address to your computer.
8.
Your
computer connects to the IP address and displays the website!
Up to four different types of
servers can be involved in a DNS lookup, depending on whether the information
is cached or not:
1.
DNS Resolver: This is your first point of contact, like a helpful
librarian who starts the search for the address.
2.
Root Nameserver: A directory for top-level domains (like .com, .org, etc.),
guiding the resolver to the right section of the internet library.
3.
TLD (Top-Level Domain) Server: A specialist for a specific domain
category, narrowing down the search for the exact shelf.
4.
Authoritative Nameserver: The guardian of IP addresses for a specific domain,
providing the final book (IP address) the resolver needs.
Not every lookup involves all
four types:
- If the resolver has the IP address cached (stored
in its memory), it can skip the search and provide a direct answer, like a
librarian who knows where a popular book is.
- If the resolver has information about the
authoritative nameserver, it can directly query that server, bypassing the
root and TLD servers, like asking a subject expert for a specific book.
Caching: This librarian remembers! DNS
servers often store recently requested addresses to speed up future searches.
Types of Queries:
- Recursive: The librarian finds the address for you
(like asking for a specific book).
- Iterative: The librarian points you to other
librarians who might know (like asking for a general genre).
- Non-recursive: The librarian already has the address in
its memory (like knowing where a popular book is).
Benefits of a Good DNS: faster websites, fewer errors, and a
more reliable internet experience.
Remember: DNS is the invisible force that
connects you to the information you crave online. So next time you visit a
website, take a moment to appreciate the magic behind the scenes!
Bloom Filters
Bloom filters are like
probabilistic bouncers for your data sets. They offer quick, space-efficient
membership checks with a slight risk of letting imposters in, but they're great
for large datasets where speed and memory matters.

What they do:
- Imagine a big party with a million guests. A
traditional guest list would be huge and slow to check.
- A Bloom filter uses a few strategically placed
bouncers (hash functions) at different doorways.
- Each bouncer asks a different "are you
X?" question, based on the guest's name (data element).
- If all bouncers say "yes," the guest is
definitely on the list (element is definitely in the set).
- But if even one bouncer says "no," the
guest might be an imposter (element might not be in the set).
Why they're useful:
- Fast & compact: Checking millions of items becomes super
quick, saving time and memory.
- Good for large sets: Ideal for massive datasets where
traditional methods like searching through lists become cumbersome.
- Trade-off with accuracy: Slight chance of false positives (imposters
getting in), but often worth it for the speed and efficiency.
Real-world uses:
- Spell checking: Quickly suggesting potential words while
you type, even if they're not exactly in the dictionary.
- Caching: Checking if a web page has been accessed
before, without storing the entire page in memory.
- Network security: Identifying potential spam or malware
before it enters your network.
Not perfect, but powerful:
- False positives can happen, but the risk can be
minimized with careful configuration.
- Not ideal for situations where absolute accuracy
is crucial.
Overall, Bloom filters are a
clever tool for fast and efficient membership checks in large datasets, even if
they have a slight chance of letting a few imposters slip through.
Consistent Hashing
Consistent hashing is a hashing
technique that performs really well when operated in a dynamic environment
where the distributed system scales up and scales down frequently.
Consistent hashing is a specific
kind of hashing in which when a hash table is re-sized i.e when the number of
servers in the server pool change, only k/n keys need to be remapped on an
average, where k is the number of keys, and n is the number of servers.

Problem: Efficiently store and retrieve data
in a dynamic distributed system (scales up/down frequently).
Solution: Consistent hashing - maps data and
servers to a virtual ring, minimizing data movement and load imbalance during
server changes.
How does consistent
hashing work ?
It has two main components- Hash Space and Hash Ring.
Hash space is the range of the output of the hash function. Those outputs are
assigned a position on the hash ring. It operates independently of the number
of servers or objects in a distributed hash table by assigning them a position
on a hash ring. If we map the hash output range onto the edge of a circle, it
would mean that the minimum possible hash value, zero, would correspond to an
angle of zero and the maximum possible value 360 degrees, and all other hash
values would linearly fit somewhere in between.
Benefits:
- Minimal remapping: Adding/removing servers affects only nearby
data items.
- Balanced load: Data evenly distributed, preventing
hotspots.
- Scalability: System handles server changes seamlessly.
Key Concepts:
- Hash functions: Map data/servers to positions on the ring.
Choose a good function (e.g., SHA-1) for randomness and collision
resistance.
- Virtual nodes: Create multiple per server for finer data
distribution and server failure resilience.
- Rendezvous hashing: Uses two-dimensional space for mapping,
simplifying data locality checks.
High-Level Design
Considerations:
- Replication: Define data redundancy strategy for
availability and fault tolerance.
- Load balancing: Adjust data distribution based on server
load/performance.
- Monitoring: Track the hash ring for potential issues
(hotspots, server failures).
Real-world examples: BitTorrent (peer-to-peer networks),
Akamai (web caches).
Distributed Consensus
In a distributed system, multiple
computers (known as nodes) are mutually connected with each other and
collaborate with each other through message passing. Now, during computation,
they need to agree upon a common value to coordinate among multiple processes.
This phenomenon is known as Distributed Consensus.
Imagine this: Maya and Akash were feeling sporty.
Akash proposed a game of cricket, his favorite pastime. Maya, a big cricket fan
herself, immediately agreed. Without needing anything further, they both
grabbed their gear and headed to the park – united in their enthusiasm for the
common activity. This mutual agreement on a shared choice, in this case,
cricket, is what we call consensus.
- What it is: Multiple computers (nodes) agree on a
single value during computations, ensuring coordination and consistency.
- Why it's needed: When nodes perform distributed tasks, they
need a common reference point to stay in sync.
- How it works: Nodes communicate using protocols (like
voting or proof-based approaches) to reach agreement.
- Challenges: Faulty nodes (crashed or behaving
abnormally) can disrupt the process, requiring robust protocols.
Key points:
- Agreement: All non-faulty nodes must agree on the same
value.
- Validity: The agreed value must come from a
non-faulty node.
- Termination: Every non-faulty node eventually agrees on
a value.
- Crash vs. Byzantine failures: Crash failures are easier to handle than
Byzantine failures, where faulty nodes actively mislead others.
Examples:
- Blockchain: Nodes agree on the state of the ledger
(transaction history).
- Google PageRank: Nodes agree on the ranking of web pages.
- Load balancing: Nodes agree on how to distribute workloads
effectively.
Consensus algorithms:
- Voting-based: Like democratic elections, nodes vote on a
value. (e.g., Paxos, Raft)
- Proof-based: Nodes provide proof (e.g., work done) to
contribute to decisions. (e.g., Proof of Work, Proof of Stake)
Distributed consensus is a
critical building block for reliable and coordinated operation in decentralized
systems.
Distributed Locking
Imagine multiple applications
sharing a resource, like a shared file or database record. To avoid collisions
and data corruption, we need Distributed Locking. It's like taking a ticket at a theme park before riding a
popular attraction, but for applications instead of people.

Here's how it works:
1.
Application requests a lock: An application asks a "lock
manager" (like a ticket booth) for exclusive access to the resource.
2.
Lock manager grants or denies: The manager checks if the resource
is locked. If free, it grants the lock to the requesting application.
3.
Application uses the resource: The application safely accesses and
modifies the resource, knowing no other application can do the same.
4.
Application releases the lock: When done, the application releases
the lock, freeing it for others.
This ensures:
- Mutual exclusion: Only one application can access the
resource at a time, preventing data conflicts.
- Correctness: Applications can rely on consistent data
without worrying about concurrent modifications.
Benefits of Distributed
Locking
- Scalability: Handles many applications accessing
resources concurrently.
- Performance: Prevents wasted effort from applications
trying to access locked resources.
- Reliability: Even if some components fail, locks remain
secure.
Examples of Distributed
Locking
- Coordinating updates to inventory levels in an
online store.
- Preventing double-booking of appointments in a
scheduling system.
- Ensuring consistent processing of financial
transactions.
Different implementations
exist
- Redis with Redlock algorithm: Lightweight but might have limitations for
strict correctness.
- ZooKeeper: Robust consensus system for highly secure
locking.
- Database-level locking: Built-in locking mechanisms in databases
like MySQL or PostgreSQL.
Choosing the right locking
approach depends on your specific needs. Consider factors like:
- Required level of correctness: Are occasional lock failures acceptable, or
is absolute accuracy crucial?
- Performance needs: How many applications need to access the
resource concurrently?
- Complexity and overhead: Can you handle the setup and maintenance of
a more complex locking system?
Redlock's flaws:
- Unnecessarily complex: For efficiency-based locks, simpler single-node
Redis locking suffices. Redlock's heavier setup isn't worth the benefit.
- Unsafe for correctness: When lock accuracy matters, Redlock fails due to:
- Timing assumptions: It relies on unrealistic expectations like
bounded network delays and clock accuracy, failing if violated (e.g.,
network delays exceeding lock expiry).
- Lack of fencing tokens: It lacks a mechanism to prevent concurrent
modifications after delays or pauses, causing data corruption.
Alternatives:
- Efficiency-only locks: Use single-node Redis with clear
documentation highlighting the approximate nature of the locks.
- Correctness-critical locks: Avoid Redlock.
- Use a proper consensus system like ZooKeeper
with fencing tokens enforced.
- Consider databases with strong transactional
guarantees.
Remember:
- Redis, when used appropriately, is a valuable
tool.
- Choose the right tool for the job: Redlock isn't
suitable for everything.
Checksum
Checksums: like digital fingerprints for files,
ensuring authenticity and completeness.
How they work: a complex algorithm (hash function)
creates a unique string (checksum) from your file. Any change, even tiny,
results in a completely different checksum.
Use cases
- Verifying downloads: compare downloaded file's checksum to
source's (provided alongside the file) to ensure no errors during
transfer.
- Checking file integrity: compare checksums over time to detect
accidental or malicious changes.
Benefits
- Peace of mind: knowing your files are genuine and
error-free.
- Security: detecting corrupted or tampered files.
- Efficiency: avoid wasting time installing or running
corrupted programs.
Getting started
- Checksum calculators: free tools like FCIV, IgorWare Hasher, or
JDigest generate checksums for your files.
- Online tools: upload your file to websites like MD5 file
checksum tool to get its checksum.
Remember: checksums are a simple yet powerful
way to protect your data and avoid trouble. Use them!
SLA, SLO, SLI
SLA (Service Level Agreement): An SLA is a contract between a service provider and the end user that defines the level of service expected from the service provider. SLAs are output-based in that their purpose is specifically to define what the customer will receive. SLAs are typically made up of one or more SLOs.
SLO (Service Level Objective): SLOs are specific measurable characteristics of the SLA such as availability, throughput, frequency, response time, or quality. These objectives must be met to achieve the SLA. They are often agreed upon between the provider and consumer of a service.
SLI (Service Level Indicator): SLIs are metrics or measures used to define the SLOs. They measure compliance with an SLO. For example, if your SLA specifies that your systems will be available 99.95% of the time, your SLO is likely 99.95% uptime and your SLI is the actual measurement of your uptime.
Here are some benefits of using SLAs, SLOs, and SLIs:
- They allow companies to define, track, and monitor the promises made for a service to its users.
- They help teams generate more user trust in their services with an added emphasis on continuous improvement to incident management and response processes.
- They ensure that metrics are closely tied to business objectives.
However, there are also some challenges:
- SLAs are notoriously difficult to measure, report on, and meet.
- These agreements often make promises that are difficult for teams to measure.
- They don’t always align with current and ever-evolving business priorities, and don’t account for nuance.
- They require collaboration between IT, DevOps, legal, and business development to develop SLAs that address real-world scenarios.
API Authentication:
1. Basic Authentication
Concept: Sends a username:password pair encoded in Base64 in the Authorization header on every request due to http header compatibility issue where http is compatible with base64.
Authorization: Basic base64(username:password)
How it works:
- Client sends credentials for every request.
- Server validates against its database.
Pros:
- Simple and easy to implement.
- Works with any HTTP client.
Cons:
- Credentials sent with every request — insecure even with HTTPS.
- No token expiration or session invalidation.
- Not scalable for APIs.
Use Case:
- Rarely used today except for internal testing or trusted systems over secure channels.
2. Bearer Token Authentication (Opaque Tokens)
Concept: Client receives an access token (random string). The token itself holds no info. Each request includes:
Authorization: Bearer <token>
How it works:
- Server issues a token and stores it in DB/cache (Redis).
- Each request validates the token from DB.
- Can be revoked instantly by deleting from DB.
Pros:
- Centralized control — easy to revoke.
- Simpler to implement than JWT.
Cons:
- Requires a database lookup for each request (slower).
- Scalability issues for large systems without caching.
Use Case:
- When you need immediate revocation (e.g., enterprise apps, admin portals).
3. JWT (JSON Web Token) Authentication
Concept: A self-contained token carrying claims (like user ID, role, expiry). Format: header.payload.signature
How it works:
- Server issues a signed token.
- No DB lookup needed — signature ensures integrity.
- Client sends token in
Authorizationheader. - Server verifies signature to trust data inside.
Pros:
- Stateless and scalable (no DB lookup).
- Tamper-proof (due to HMAC or RSA signature).
- Flexible (custom claims, expiration, roles).
Cons:
- Cannot be easily revoked until expiry.
- Larger in size compared to opaque tokens.
- Must handle refresh tokens for rotation and revocation control.
Use Case:
- Modern REST APIs and microservices where performance and scalability matter.
Tip: Use token versioning or refresh tokens to control JWT invalidation.
4. OAuth 2.0
Concept: An authorization framework, not direct authentication. Allows a third-party app to access a user’s data without sharing credentials.
Flows:
- Client Credentials Flow: For M2M (machine-to-machine).
- Authorization Code + PKCE: For frontend/mobile apps.
- Implicit Flow (deprecated): For legacy SPAs.
How it works:
- User grants consent to a third-party app via an authorization server.
- The app receives an access token to access specific resources with refresh token.
Pros:
- Industry standard for delegated access.
- Highly secure with PKCE and scopes.
- Fine-grained permission control.
Cons:
- Complex to implement correctly.
- Pure OAuth2 does not identify the user (only authorizes).
Use Case:
- Third-party integrations (Google login, Twitter API access).
5. OpenID Connect (OIDC)
Concept: An authentication layer built on top of OAuth 2.0. It adds an ID Token (JWT) to identify the user.
How it works:
- Uses OAuth2 flow.
- Returns both access token (for APIs) and ID token (for user info) with refresh token.
Pros:
- Handles both authentication and authorization.
- Widely adopted for modern SSO (Single Sign-On).
- ID Token audience restriction prevents misuse.
- Access token and refresh token are revocable.
Cons:
- Slightly more complex setup.
- Must ensure correct audience and nonce validation.
Use Case:
- Login systems using identity providers (Google, Microsoft, Auth0).
6. SSO (Single Sign-On)
Concept: User logs in once and gains access to multiple systems without re-login.
Flavors:
- SAML (Security Assertion Markup Language): XML-based; enterprise-grade; older but very secure.
- OIDC: JSON-based; modern web and mobile.
Pros:
- Better UX (one login across apps).
- Centralized access control and logout.
Cons:
- Complex setup and dependency on identity provider uptime.
Use Case:
- Enterprises using multiple internal systems or SaaS platforms.
7. SCIM (System for Cross-domain Identity Management)
Concept: A protocol for identity lifecycle management — not authentication itself. Used to provision, de-provision, and sync user accounts across systems.
How it works:
- When a user is created/deleted in one system, SCIM syncs changes automatically to others.
Pros:
- Automates user management and deactivation.
- Reduces orphaned accounts and security risks.
Cons:
- Adds integration overhead.
- Not directly tied to login/auth flow.
Use Case:
- Large organizations managing users across multiple SaaS apps (e.g., Okta, Azure AD).
🔒 Security & Implementation Tips
| Tip | Explanation |
|---|---|
| Always use HTTPS | Prevents eavesdropping and credential leaks. |
Store tokens in HttpOnly cookies | Protects against XSS but vulnerable to CSRF. |
| Avoid storing tokens in localStorage | Easy target for XSS. |
| Use short-lived access tokens + refresh tokens | Minimizes damage if token is stolen. |
| Implement PKCE for SPA/native apps | Adds protection against code interception. |
| Use OAuth 2.0 for 3rd-party access | Best for delegated permissions (e.g., “Sign in with Google”). |
| Revoke refresh tokens on logout | Ensures complete session termination. |
⚙️ How IdentityServer Handles Token Storage & Revocation
IdentityServer (v4 and later, including Duende IdentityServer) uses persistent storage (usually a database) to manage the lifecycle of:
| Token Type | Storage? | Reason |
|---|---|---|
| Access Token (JWT) | ❌ Not stored by default | JWTs are stateless and verified by signature |
| Access Token (Reference Token / Opaque) | ✅ Stored | Enables instant revocation & introspection |
| Refresh Token | ✅ Stored | Needed to issue new tokens and handle revocation |
| Authorization Code | ✅ Stored temporarily | Used once, then deleted |
| User Consent & Device Code | ✅ Stored | For tracking grants and authorization decisions |
🧩 1. Access Token Options
In IdentityServer, you can choose between:
- JWT access tokens (default) → stateless, verified by signature
- Reference tokens (opaque) → stored in DB, validated by introspection endpoint
Example in config:
new Client
{
ClientId = "api-client",
AllowedGrantTypes = GrantTypes.Code,
AccessTokenType = AccessTokenType.Reference, // enables DB storage
AccessTokenLifetime = 3600,
AllowOfflineAccess = true
};
📘 Why Reference Tokens Are Revocable
- Stored in the PersistedGrants table.
- When revoked (logout, admin action, session timeout), they’re simply deleted.
- Any further use of that token fails introspection.
🧩 2. Refresh Token Handling
IdentityServer always stores refresh tokens — because they are stateful by design and used to issue new access tokens.
They’re stored in the same PersistedGrants table (or a specialized store) with fields like:
- Key (token identifier)
- Subject ID (user)
- Client ID
- Expiration
- Status (active/revoked)
- Scopes
When revoked or rotated, the record is marked invalid or deleted.
🧩 3. Token Revocation in IdentityServer
OIDC-compliant /revoke endpoint:
POST /connect/revocation
Authorization: Basic client_id:client_secret
Content-Type: application/x-www-form-urlencoded
token=xyz123&token_type_hint=refresh_token
Behind the scenes:
- IdentityServer looks up the token in the DB.
- Marks it as revoked or deletes it.
- All future uses of that token fail.
If it’s a reference access token, it’s invalidated immediately. If it’s a JWT access token, only the refresh token is revoked (no new tokens can be minted).
🧩 4. Persisted Grant Storage Example
Typical tables in IdentityServer’s DB (using EF Core):
| Table | Purpose |
|---|---|
PersistedGrants | Stores refresh tokens, reference tokens, device codes |
DeviceCodes | Device Flow support |
Keys | Cryptographic signing keys |
Client / ClientScopes | Registered clients and scopes |
🧠 Key Insight
| Token Type | Stored | Revocable | Why |
|---|---|---|---|
| JWT Access Token | ❌ No | ⚠️ Not directly | Stateless; can only expire or be invalidated by token version check |
| Reference Access Token | ✅ Yes | ✅ Yes | Stored in DB; can be deleted |
| Refresh Token | ✅ Yes | ✅ Yes | Always stored for rotation/revocation |